

Python Web Scraping
In all seriousness when scraping make sure your code has as little impact on the server as possible and just generally follow Wheaton's Law.
First things first starting from a fresh Raspberry Pi or similar let's go ahead and install virtualenv so we can have a contained python environment without affecting other things.
sudo apt install virtualenv -y
Then as a prelude to using selenium we need to install firefox and some drivers. Firefox is simple enough:
sudo apt install firefox-esr -y
Unfortunately gecko drivers are less so. Checking GitHub for the drivers we find that there are no longer arm drivers available so we will need to use an old (Jan 2019) version or build the drivers from source using Rust. We briefly covered some rust in an earlier post, and I've been playing with it on and off for a while so this should not be an issue.
If Rust is not already installed:
curl https://sh.rustup.rs -sSf | sh
At this point you need to restart your shell to make sure cargo is accessible. Then download the source code and unpack it
wget https://github.com/mozilla/geckodriver/archive/refs/tags/v0.30.0.tar.gz -O - | tar -xz
Then flip the switch and go find something to do - no really this is going to take a while on a pi, probably ~20m.
cd geckodriver-0.30.0 && cargo build --release
It's worth noting you can cross compile this on a more powerful machine, just remember if you want to do so you need to make sure you've got the correct target toolchain and packages.
For now lets copy our shiny new driver onto our path. You can also remove the folder if you want afterwards.
sudo cp ~/geckodriver-0.30.0/target/release/geckodriver /usr/local/bin
Then lets set up a virtual environment for our python code to run in. Our code is going to be used scrape the local government website to find out when the next bin day is and notify us.
mkdir ~/.virtualenvs && cd ~/.virtualenvs && virtualenv binDayEnv && cd binDayEnv && source bin/activate && mkdir binDay && cd binDay
lets install our requirements using pip
echo "selenium" >> requirements.txt && pip install -r requirements.txt
Finally lets write some code in binDay.py starting off with this basic from the docs.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()
Running it with python3 binDay.py ...returns an error. Not a particularly helpful one either "Message: Process unexpectedly closed with status 1", and I'm half way to google before I realise I never specified we were running on a headless machine. Oops. Quickly fixing that we get:
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.keys import Keys
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_source
driver.close()
And this time when we run it the code runs properly. We're expecting the assertions to be true, so there shouldn't be output, but it seems that since the example was published find_element_by_name has been deprecated so we get a warning. Not an issue we just wanted to make sure all our setup was working correctly.
Now that everything is in place we need to find our website for bin times. Originally I was going to use 10 Downing Street for this example, but the relevant waste website fell over and served a 404 when I tried, so I gave up and picked a random city spot on google maps instead which leads us to Manchester and their bin collection website.
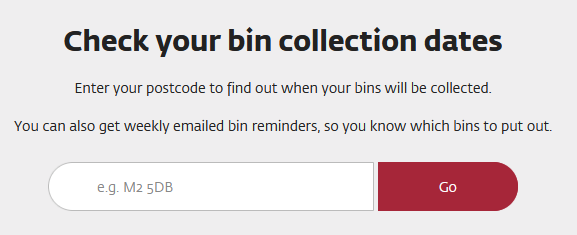
First it asks us for a post code, for which we're going to use M4 5HF, and then we're using house number 41 as 42 was not available. From opening the website in a normal browser we can see that the postcode field is nicely labelled with id="mcc_bin_dates_search_term" and after submitting the postcode the dropdown list has id="mcc_bin_dates_uprn". This is enough to start:

from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get('https://www.manchester.gov.uk/bincollections')
elem = driver.find_element(By.ID, 'mcc_bin_dates_search_term')
elem.clear()
elem.send_keys("M4 5HF")
elem.send_keys(Keys.RETURN)
selector = driver.find_element(By.ID, 'mcc_bin_dates_uprn')
driver.close()
You'll likely find that you get an error about being unable to find an element with id="mcc_bin_dates_uprn". This is expected, as we've not given the page time to load. To fix this we're going to wait for the element, and while we're at it do the same for the original post code box.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get('https://www.manchester.gov.uk/bincollections')
elem = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_search_term'))
)
elem.clear()
elem.send_keys("M4 5HF")
elem.send_keys(Keys.RETURN)
selector = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_uprn'))
)
input("It worked")
driver.close()
Now that we have this working we can look at selecting our address from the list. Looking through the list in the developer console we can see some value numbers for each entry. These numbers are in fact UPRN numbers and are unique to an address. If you're interested you can look up your address. This is perfect for our use as we can find the value matching our UPRN, but we could also have searched for the address text instead with very similar results.
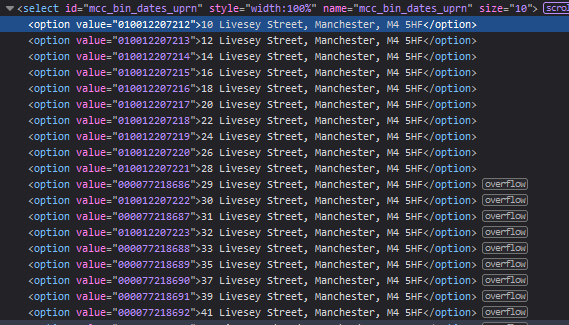
Checking the results for our address gives the UPRN number as 000077218692 so let's go ahead and expand upon our code.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get('https://www.manchester.gov.uk/bincollections')
elem = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_search_term'))
)
elem.clear()
elem.send_keys("M4 5HF")
elem.send_keys(Keys.RETURN)
selector = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_uprn'))
)
Select(selector).select_by_value('000077218692')
submit = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_submit'))
)
submit.click()
input("It worked")
driver.close()
Here we're identifying the select class which is what is being used for our list, and then once identified we're using the select class in selenium to choose our address using the UPRN number discussed earlier. We're then finding and clicking the submission button. Now the finish line is in sight - we can see our results we simply need to parse them from the results below.
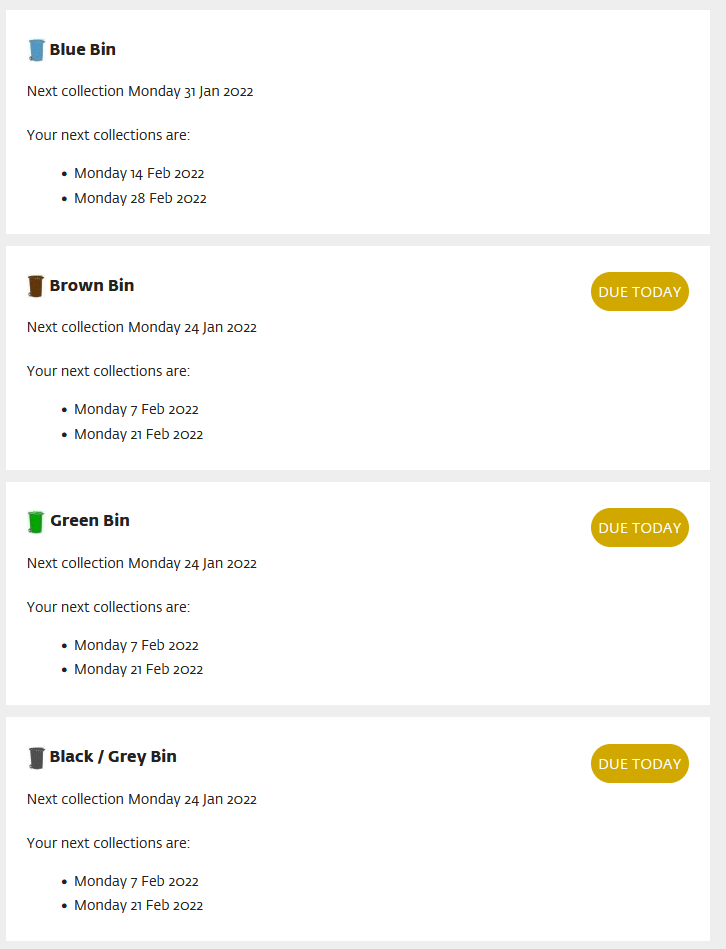
Looking through the source we can see that the data is inside several divs with class="collection" inside several nested divs inside a section:
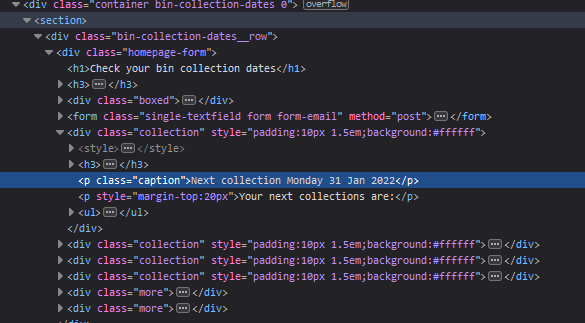
We're going to wait for the divs with class="collection" to be available before iterating over all of them to simply grab the h3 headers followed by the text element below them.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get('https://www.manchester.gov.uk/bincollections')
elem = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_search_term'))
)
elem.clear()
elem.send_keys("M4 5HF")
elem.send_keys(Keys.RETURN)
selector = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_uprn'))
)
Select(selector).select_by_value('000077218692')
submit = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_submit'))
)
submit.click()
results = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, 'collection'))
)
for result in results:
print(f'{result.find_element(By.XPATH,".//h3").text} - {result.find_element(By.XPATH,".//p").text}')
driver.close()
Ok so we've now pretty much finished, our code works well. The issue here is one of human nature (specifically mine). With this script I have to log in and run it, not to mention I need to remember that it's bin day in the first place.
To resolve this we're going to set up a cron job so that the code is run automatically and also use a wonderful little library called apprise to notify us. Apprise allows us to send notifications to a wide variety of services, but here we are going to use telegram as it's one of the simpler ones to set up and demonstrate.
First let's update our requirements.txt to contain apprise, and then update using pip.
echo "apprise" >> requirements.txt && pip install -r requirements.txt
Now that we have apprise installed we need to set up a telegram bot account. In telegram we message the "BotFather" as below to create our bot (taking note of the token 5032278541:AAE7Dx2Tnq_ukwtqzG3tZi6sYHkg7xhCGM8 in this case):
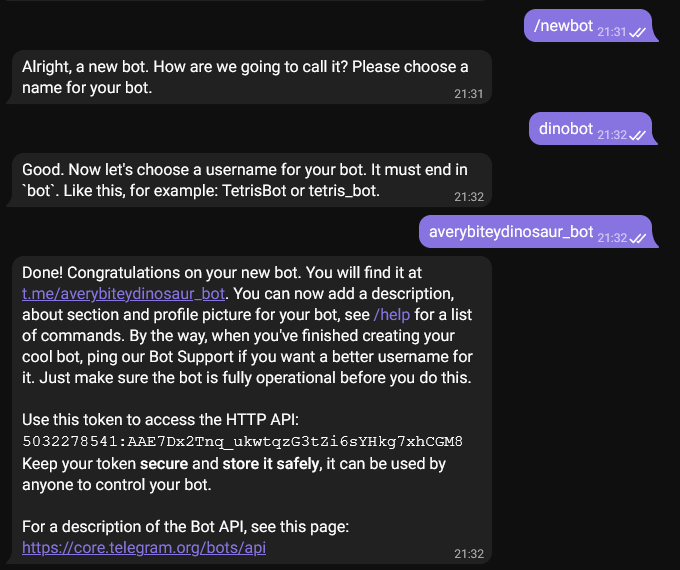
Then we use the link given https://t.me/averybiteydinosaur_bot to start a conversation with the bot, and click start. This will be enough to initiate a chat with the bot, allowing us to use the token and go to https://api.telegram.org/bot5032278541:AAE7Dx2Tnq_ukwtqzG3tZi6sYHkg7xhCGM8/getupdates where we will see some JSON for the bot from which we can get a chat ID:
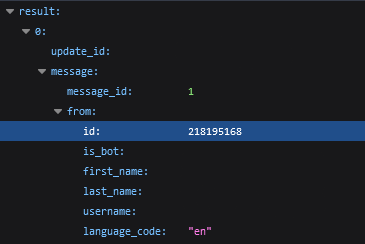
Here the ID is 218195168. Putting these both together we can get a link for our code to be able to send messages and modify our python as below:
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import apprise
appr = apprise.Apprise()
appr.add('tgram://5032278541:AAE7Dx2Tnq_ukwtqzG3tZi6sYHkg7xhCGM8/218195168')
options = Options()
options.add_argument('--headless')
driver = webdriver.Firefox(options=options)
driver.get('https://www.manchester.gov.uk/bincollections')
elem = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_search_term'))
)
elem.clear()
elem.send_keys("M4 5HF")
elem.send_keys(Keys.RETURN)
selector = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_uprn'))
)
Select(selector).select_by_value('000077218692')
submit = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'mcc_bin_dates_submit'))
)
submit.click()
results = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, 'collection'))
)
bins = ''
for result in results:
bins += f'{result.find_element(By.XPATH,".//h3").text} - {result.find_element(By.XPATH,".//p").text}\n'
driver.close()
appr.notify(
title='Bin Reminder',
body=bins
)
Running our code we can see our bot received the message:
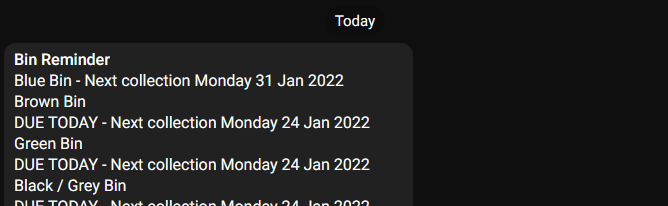
So now all we need to do is add a cron job so that our code runs automatically. To do this we use the command crontab -e at which point we will be asked which editor we want to use. Once selected we need to add the following to the file before saving and exiting:
PATH=/usr/bin:/bin:/usr/local/bin
0 20 * * 0 /home/dino/.virtualenvs/binDayEnv/bin/python3 /home/dino/.virtualenvs/binDayEnv/binDay/binDay.py
This is specifying that at 0 minutes (on the hour), at hour 20 (8pm), ignoring day of the month, ignoring month of the year, and on day 0 of the week (Sunday) our code will be run. We've specified a path for python so that it uses our virtual environment, and also the path of the script to run. You may want to change these values for testing, or just because you want it to trigger at a different time. Note that we've also had to change our PATH as the default PATH would not contain the gecko drivers that we compiled - make sure this does not interfere with other cronjobs if you have any.
And with that we're done! Buuuuuuut just quickly I'd like to take a look at York's bin collection which was the first one I came across that used an API. To use it you can simply look up your UPRN as we mentioned before and add it to the address to instantly get back a JSON response with your bin days. For example https://waste-api.york.gov.uk/api/Collections/GetBinCollectionDataForUprn/100050535540 spits out exactly what we're looking for, no muss no fuss, we can directly take the information and use it:
import requests
import apprise
appr = apprise.Apprise()
appr.add('tgram://5032278541:AAE7Dx2Tnq_ukwtqzG3tZi6sYHkg7xhCGM8/218195168')
resp = requests.get("https://waste-api.york.gov.uk/api/Collections/GetBinCollectionDataForUprn/100050535540")
json = resp.json()
bins = ''
for binType in json["services"]:
bins += f'{binType["service"]} - {binType["nextCollection"]}\n'
appr.notify(
title = 'Bin Reminder',
body = bins
)
As you can see the code is considerably shorter, it returns a response a lot faster as we're not having to load selenium, and less work is required from the server (no website to worry about). So even though we can overcome a lack of API/computer readable information, given the option it's almost always going to be preferable to have an API available.